Common data structures in the wild
A data structure is a scheme for organizing data in computer memory. The way in which the data is organized affects the performance of a program for different tasks like data access, insertion, deletion or search.
The concept of data structures in computer science is a core concept continuously improving with new strategies to organize and access data being used to solve new scenarios / use cases, or simply to improve performance of existing ones. And, most importantly, knowing how your data can be structured in a system is a key aspect for successfully solving complex problems or tasks.
The purpose of this blog post is to encompass the most commonly, widely used data structures in computer science at the present time in a easy-to-read cheetsheet with the pros, cons and use case scenarios associated with each structure for my personal use. Though be aware that this list is not the most up-to-date list with the latest state-of-the-art data structures out there (nor a thorough one). However, whenever a new or improved data structure that caughts my eye that solves a problem in an optimal way is interesting, I’ll update this post with newer information accordingly.
As a side note, in this gist I’ve put the most efficient implementations in Python I am aware of to reduce the need to be constantly searching for the most efficient implementation of data structures. Although this is a process that is continously being improved and updated, and many structures do not have any implementation reference available yet, if you happen to know a more efficient algorithm to implement one or more of this structures in Python (or any language) feel free to ping me :).
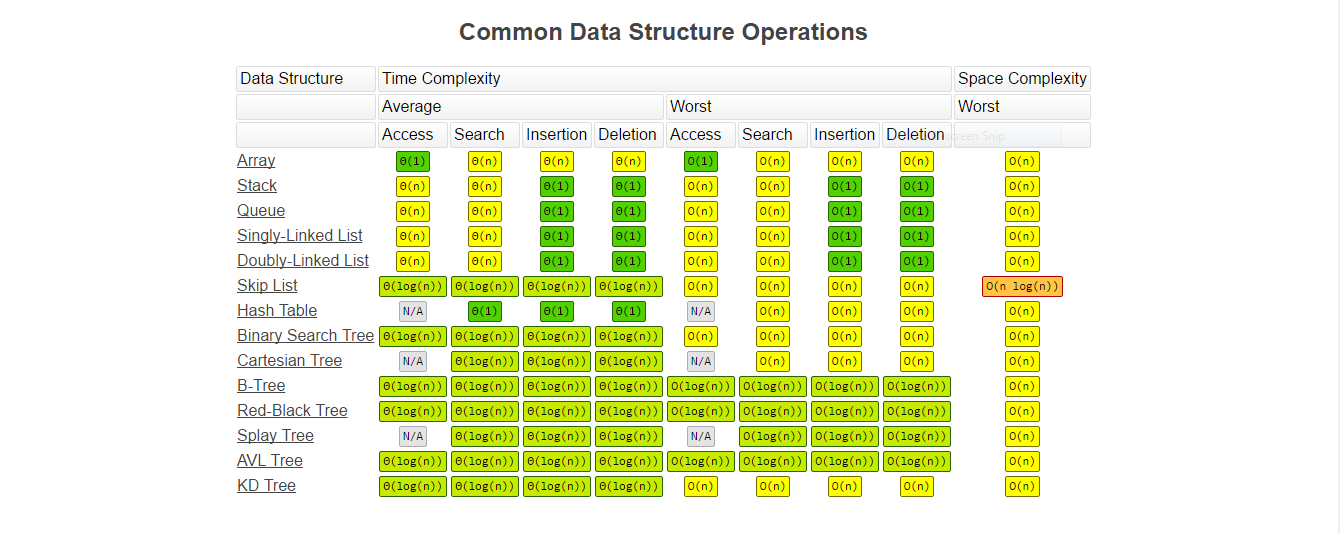
Note: Image taken from [1].
Common Data Structures: Pros and Cons
| Data Structure | Pros | Cons | Use Cases |
|---|---|---|---|
| Arrays | Easy to create and use Direct indexing: O(1) Sequential access: O(n) |
Sorting: O(nlog(n)) Searching: O(n) and O(log(n)) if sorted Inserting and deleting: O(n) because of shifting items. |
Sequential data reads (optimal use of L1, L2, and L3 cache memory) |
| Linked Lists (Single, Double) | Inserting and deleting: O(1) Sequential Access: O(n) |
No direct access (only sequential access) Searching: O(n) Sorting: O(nlog(n)) Uses more storage space compared to Arrays |
Collections: Mutable arrays, Sparse Matrices, Trees, Graphs, Queues, Stacks Dynamic Memory Allocation |
| Skip lists | Inserting and searching on ordered sequences: O(log(n)) | Uses more storage than Arrays, Lists of Trees: O(nlog(n)) | Ordered sets implentation Indexes Lock-free shared memory Highly scalable concurrent priority queues with less lock contention Lock-free concurrent dictionaries 3D Sparse Grid for Robot Mapping systems Moving medians |
| Stacks | Push/Add: O(1) Pop/Remove: O(1) Peek: O(1) |
Searching: O(n)
Random Access: O(n) |
Track method calls or the state of a program Depth-first search Expression Handling |
| Queues | Push/Add: O(1) Pop/Remove: O(1) Peek: O(1) |
Searching: O(n)
Random Access: O(n) |
Network packets I/O requests |
| Hash Tables / Maps (*) | Inserting and deleting: O(1) + Hashing & Indexing (amortized) Direct access: O(1) + Hashing & Indexing |
Some overhead (requires a bit more memory space compared to arrays) Retrieval of elements not guaranteed to be in specific order Searching for a value (without knowing it’s key) |
Caching Look-up Tables Database indexing Sets Graph representation Fast insert / access storage |
| Sets | Checking membership / value existence Avoid duplicates |
Limited use cases Performance depends on underlying implementation (hash table vs tree) |
Finite unique collection representation |
| Trees | Extends the capability of a normal array Inserting, deleting and accessing: O(log(n)) Fast search of values: O(log(n)) Retrieval of elements is in order Scales better than linked lists |
Bad performance when unbalanced: O(n) Some overhead Slower access than arrays Bad performance for concurrent access compared to skip lists Not as optimized for cpu cache levels as arrays (**) Grows slower than linked lists |
Efficiently maintains a dynamically changing dataset in sorted order Database indexing: Element comparison in a less than / greater than manner Binary space partition: 3D object renderingBinary Tries: Networking (storing router-tables) Hash Trees: p2p programs, specialized image-signatures in which a hash needs to be verified, but the whole file is not available Heaps |
| Heaps | Min/Max search: O(1) Inserting: O(log(n))
Min/Max Deletion: O(log(n)) |
Searching and deleting: O(n) |
Efficient priority-queues Process scheduling Path-finding: Robotics, video games |
Notes
(*): In Java, hash tables are inherently synchronized and hence are thread safe while the hash maps are not thread safe.
(**): Fractal Prefetching B-Trees are an improvement on this issue.
Common Binary Search Trees
| Data Structure | Pros | Cons | Use Cases |
|---|---|---|---|
| AVL Trees | Great for static / slow updating systems [2] Faster search than Red–Black trees for lookup-intensive applications [2] |
Slow inserts and deletes if unbalanced (even if slightly) [2] Slow for fast updating systems [2] |
Fast data search [2] |
| Binary Search Trees | Simplest implementation of all trees [3] Sequential storage on disk [4] Faster insertion and deletion than other trees (no rebalancing mechanism) [4] Smaller memory footprint [4] |
Poor performance if not balanced [5] No self-balacing mechanisms [3] |
Sorting algorithms [4] Main-memory data structures [4] Basic framework for other tree implementations [4] |
| B-Trees | Better for disk I/O (also check B+-Trees) [6][7] Uses memory caching to offset searching costs [7] |
Expensive insertion and deletion for trees with a large branching factor [7] |
Suited for storage systems that read and write relatively large blocks of data: Databases, filesystems [7] |
| Cartesian Trees | Simple implementation [8] The lowest common ancestor between two nodes is the minimum node between them [8] Efficient operations on sub-trees: O(log(n)) [9] |
Search, insertion and deletion: O(n) [1] Higher overhead compared to other trees [9] |
Sorting [10] Treaps [10] Suffix trees [10] Efficiently solves the range minimum query (RMQ) by finding the lowest common ancestor (LCA) [11] |
| KD Trees | Fast search for low dimensional data (e.g., 2D/3D space) [13] |
Degradation in performance with high-dimensional data [13] |
Organizing points in a k-dimensional space [13] Multidimensional search: range-search, nearest-neighbour [12][13] |
| Hash / Merkle Trees | Creates a distinct ”root” for each unique set of values [14] Hability to reconstruct the root and / other branches [14] |
Size of the proofs increase logarithmically with the number of values and the branching factor of the tree [17] Susceptible to second-preimage attacks if not implemented correctly [14] |
Hash-based cryptography [15] File systems: IPFS, Btrfs, ZFS [14] Distributed version control systems: Git, Mercurial [14] Blockchain: Bitcoin [14] Peer-to-peer networks: Ethereum [14] Certificate authorities [16] NoSQL databases [14] |
| Red-Black Trees | Faster insertion and removal than AVL tree [18] | Slower search than AVL trees for lookup-intensive applications [2] |
Libraries: map, multimap, multiset [18] Schedulers [20] Collections: Associative Arrays, Sets, Hash Maps, Persistent Data Structures [19] |
| Splay Trees | Access of recently searched items in O(1) [21] Better read performance compared to AVL trees [21] Smaller memory footprint: does not store additional information as AVL / Red-Black Trees [23] |
Height can be linear [23] Trees are not strictly balanced [22] Difficult to use in multi-threaded environments: defeats memory caches and can create unnecessary lock contention [23][24] Worse performance for random access patterns compared to AVL / Red-Black Trees [23] |
Virtual memory [21] Networking [21] File systems [21] Compilers [21] Recommended searches [24] Data compression algorithms [25] |
| Tries | pInsert and find strings in O(L) [28] Easily print all words in alphabetical order [28] |
Huge memory for storing the strings [28] |
Sorting algorithms [26] Autocomplete dictionary [26] Spell checking [26] Longest prefix matching [27] Browser history [27] |
Note: For a visual representation of a B-Tree vs a B+-Tree see here.
{kind=link}
Heaps
This is not an exaustive list of heap implementations, but you should be able to find the most commonly used heaps algorithms in the wild in the following table.
| Operation | find-min | delete-min | insert | decrease-key | meld |
|---|---|---|---|---|---|
| Binary | O(1) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) |
| Leftist | O(1) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) |
| Binomial | O(1) | O(log(n)) | O(1) | O(log(n)) | O(log(n))** |
| Fibonacci | O(1) | O(log(n))* | O(1) | O(1)* | O(1) |
| Pairing | O(1) | O(log(n))* | O(1) | O(log(n))* | O(1) |
| Brodal | O(1) | O(log(n)) | O(1) | O(1) | O(1) |
| Rank-pairing | O(1) | O(log(n))* | O(1) | O(1)* | O(1) |
| Strict-Fibonacci | O(1) | O(log(n)) | O(1) | O(1) | O(1) |
| 2-3 Heap | O(log(n)) | O(log(n))* | O(log(n)) | O(1) | ? |
(*): Amortized time.
(**): n is the size of the larger heap.
Conclusion
In this post you’ll find a list of the most commonly used data structures with a list of the pros and cons of the use for each one, so you can have a more educated insight of why and when to use such a data structure in your solutions.
As a personal note, this was a fun exercise to do and highly encourage anyone to take a look at the landscape of existing data structures. It is safe to say that plenty more state-of-the-art data structures will be researched, designed and implemeted such that the limits of space and time complexity goal posts will continually be increased and more performant data strucures will emerge.
There’s plenty of room for improvement for those who have the drive to research such problems, and there’s alot to profit from for all of those who care about using the most elegant and/or efficient solution out there.
Hope you found this useful.
Cheers
Sources and Useful Links
[1] https://www.bigocheatsheet.com/
[2] https://nyln.org/avl-tree-pros-and-cons-list
[3] https://en.wikipedia.org/wiki/Binary_search_tree
[4] https://stackoverflow.com/questions/2130416/what-are-the-applications-of-binary-trees
[5] https://developpaper.com/figure-out-the-advantages-and-disadvantages-of-each-tree/
[6] https://en.wikipedia.org/wiki/B-tree
[7] https://web.stanford.edu/class/archive/cs/cs166/cs166.1146/lectures/02/Small02.pdf
[8] https://en.wikipedia.org/wiki/Cartesian_tree
[9] https://sudonull.com/post/170748-Cartesian-tree-Part-3-Cartesian-tree-by-implicit-key
[10] https://www.geeksforgeeks.org/cartesian-tree-sorting/
[11] https://cp-algorithms.com/graph/rmq_linear.html
[13] https://en.wikipedia.org/wiki/K-d_tree
[14] https://en.wikipedia.org/wiki/Merkle_tree
[15] https://en.wikipedia.org/wiki/Hash-based_cryptography
[16] https://www.codementor.io/blog/merkle-trees-5h9arzd3n8#use-cases-for-merkle-trees
[17] Dynamic Merkle B-tree with Efficient Proofs
[18] https://www.geeksforgeeks.org/red-black-tree-vs-avl-tree/
[19] https://en.wikipedia.org/wiki/Red-black_tree
[20] https://en.wikipedia.org/wiki/Completely_Fair_Scheduler
[21] https://www.geeksforgeeks.org/splay-tree-set-1-insert/
[22] https://www.javatpoint.com/splay-tree
[23] https://en.wikipedia.org/wiki/Splay_tree#Disadvantages
[24] https://stackoverflow.com/questions/47654564/splay-tree-real-life-applications
[25] https://dl.acm.org/doi/10.1145/63030.63036
[26] https://en.wikipedia.org/wiki/Trie#Applications
[27] https://iq.opengenus.org/applications-of-trie/
[28] https://www.geeksforgeeks.org/advantages-trie-data-structure/
http://cs-www.cs.yale.edu/homes/aspnes/classes/223/notes.pdf
Tree implementations in C (2005): https://adtinfo.org//